
One of the projects I worked on recently involved migrating an application from a single HPE Superdome Flex server running Windows Server 2012 R2 to 12 Windows Server 2019 servers. The application was a sophisticated outage forecasting system that, among other things, generated a 3-year forecast weekly. This forecast took 3 days to run using a third of the server’s 144 Intel Xeon cores. In comparison, each of the 12 new servers only had 16 to 32 cores.
Although it may have worked to run the forecast on one of the 32 core servers and call it a day, the report would have taken four or five days to run and the customer wasn’t happy with it taking three days to begin with. The application needed to be modified to run as a distributed system.
I immediately ran into a problem. The application was written in Python 2.7 because it had to integrate with PSSE 33, Siemens’ Power System Simulation for Engineers tool, and it was running on Windows. This combination severely limited my options. The best and most popular option, Celery, dropped Windows support with its 4.0 release in 2016. We’d be stuck using Celery 3.1 and have no upgrade path. Still, the performance gains would be worth it and we could always migrate to a different distributed task queue when upgrading PSSE (and Python versions with it) in the future.
Celery Overview
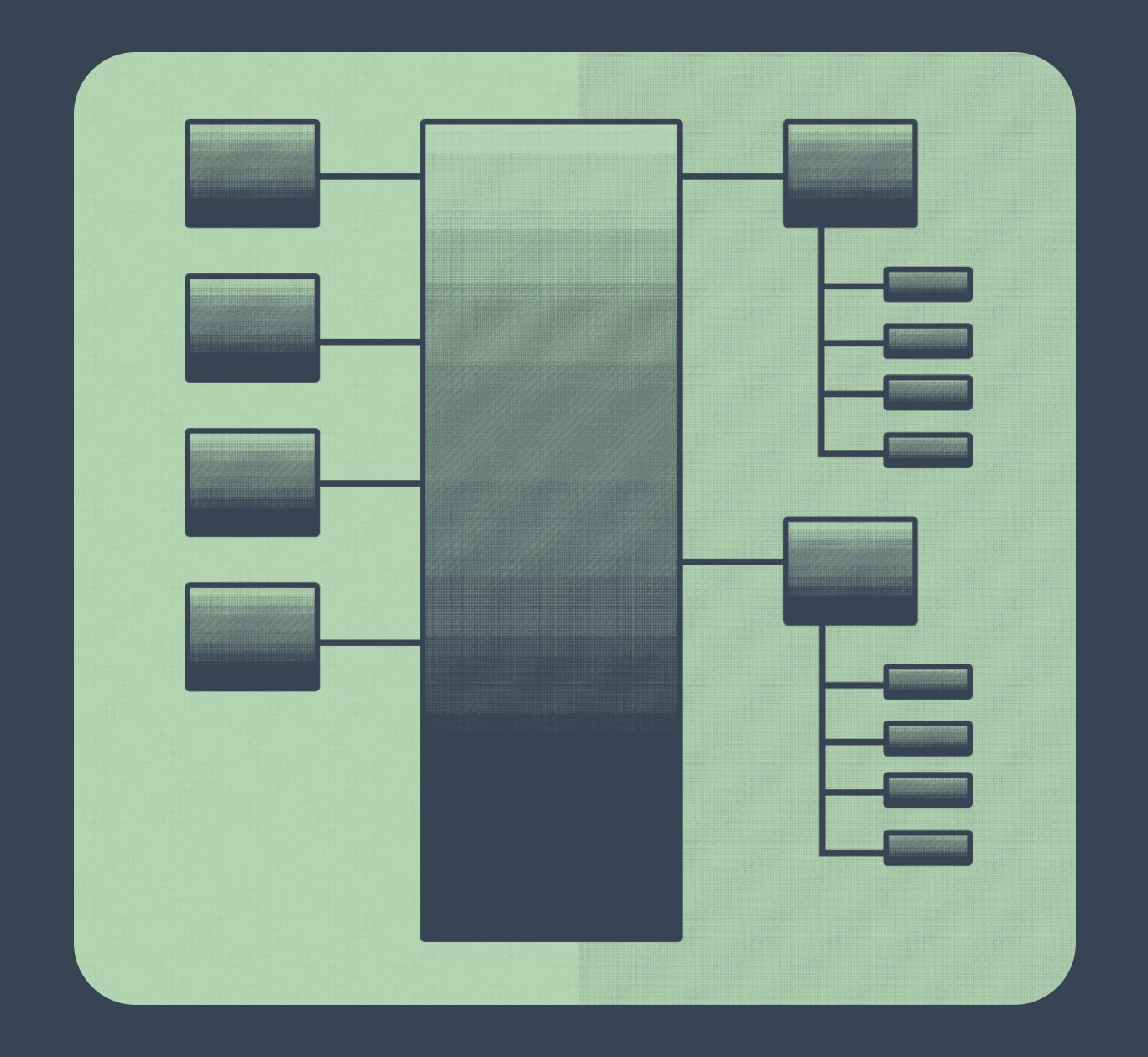
Celery is a distributed task queue library that allows you to execute time-consuming or resource-intensive tasks asynchronously. It allows you to scale processing in a distributed system by adding more worker processes to existing workers or by adding workers to more servers.
Celery tasks are Python functions or methods that you execute asynchronously.
A message queue, typically RabbitMQ or Redis, is used for communication between the producers (applications sending task messages / requests) and consumers (workers executing tasks).
A Celery worker spawns the number of worker processes specified by the concurrency option. Celery workers monitor the message queue, receive task messages, and dispatch them to one of their worker processes. Worker processes execute the tasks.
Implementation
Converting the application to run as a distributed system turned out to be incredibly straightforward. It was already using the Python multiprocessing module to execute tasks in parallel and had a task manager and worker class to facilitate that. I just needed to create versions of those classes that would send task messages instead of executing tasks locally and use them when generating the 3-year forecast.
Here’s an example celery app that uses Redis as the broker. The run_task function takes a task as a parameter, executes it, and returns the task id.
from celery import Celery
from celery_app_env import REDIS_HOST
celery_app = Celery("celery_app", broker=REDIS_HOST, backend=REDIS_HOST)
celery_app.conf.CELERY_DEFAULT_QUEUE = 'celery_queue'
celery_app.conf.CELERYD_TASK_TIME_LIMIT = 60 * 60
@celery_app.task()
def run_task(task):
print("Task Started: " + task.task_id)
task.execute()
print("Task Finished: " + task.task_id)
return task.task_idThis command starts a celery_app worker with 4 worker processes and a log level of info. If concurrency isn’t set, Celery defaults to the number of CPUs available on the server.
celery -A celery_app worker --loglevel=info --concurrency=4
During development, I ran Celery workers in their own command prompts. In production, I used NSSM, the Non-Sucking Service Manager, to install and run Celery workers as Windows services. NSSM can be used to set the stdout and stderr log locations and other configuration settings.
Here’s an example of a task that can be run using the Celery run_task function. It takes a task id and the number of seconds it should sleep (when executing) as parameters.
import time
class SleepTask():
@property
def task_id(self):
return self._task_id
@property
def seconds(self):
return self._seconds
def __init__(self, task_id, seconds):
self._task_id = task_id
self._seconds = seconds
def execute(self):
time.sleep(self.seconds)
Here’s an example of a worker that takes a task as a parameter and executes it using Celery. It inherits from the multiprocessing module’s Process class. This process starts with .start() and ends with the .join() blocking call. The delay command sends the task message and the get command is a blocking call that waits for the result.
from multiprocessing import Process
from celery_app import run_task
TASK_TIMEOUT = 60 * 60
class DistributedWorker(Process):
@property
def task(self):
return self._task
def __init__(self, task):
super(DistributedWorker, self).__init__()
self._task = task
def run(self):
task = run_task.delay(self.task)
result = task.get(timeout=TASK_TIMEOUT)
And here’s an example that uses the SleepTask class, DistributedWorker class, and celery app to execute 50 sleep tasks using Celery. All 50 processes start up and send their task message to the Redis broker. Celery workers then execute the task, 4 at a time (in our example).
from tasks import SleepTask
from workers import DistributedWorker
def main():
tasks = []
for i in range(50):
task_id = str(i)
seconds = i
task = SleepTask(task_id, seconds)
tasks.append(task)
workers = []
for task in tasks:
worker = DistributedWorker(task)
workers.append(worker)
worker.start()
print("Worker Started: " + worker.task.task_id)
for worker in workers:
worker.join()
print("Worker Joined: " + worker.task.task_id)
if __name__ == '__main__':
main()
Debugging
When I deployed to production and started running the 3-year forecast everything appeared to run great at first. Then the number of worker processes running on each server started to slowly go down and some workers even appeared to stop running completely with hundreds of tasks still left to execute. It took me a while to figure out what was happening. Celery workers were prefetching tasks (up to 128 tasks on a 32 core server) and handing them off to their worker processes unevenly. In doing so they were starving other workers or even some of their own worker processes. These changes fixed the problem.
celery_app.conf.CELERYD_PREFETCH_MULTIPLIER = 1
celery_app.conf.CELERY_ACKS_LATE = TrueCELERYD_PREFETCH_MULTIPLIER is the number of unacknowledged task messages a worker can reserve multiplied by the number of worker processes. If set to 1, the worker will only reserve one unacknowledged task message per worker process at a time.
CELERY_ACKS_LATE changes the behavior of celery to only acknowledge task messages after the task has been executed, not before.
celery -A celery_app worker --loglevel=info --concurrency=4 -Ofair
The -Ofair option makes workers only assign tasks to worker processes that aren’t already executing a task.
Setting CELERYD_PREFETCH_MULTIPLIER to 1 and CELERY_ACKS_LATE to True attempts to divide tasks evenly between workers while the -Ofair option tries to divide tasks evenly within workers (between worker processes). This is ideal for long running tasks as no workers or worker processes hoard tasks. It is bad for short running tasks as a lot more time is wasted on communication between the broker, workers, and worker processes (which is why it’s not the default).
Conclusion
Running the application as a distributed system increased the number of tasks it could execute at one time from 48 to 224. I also installed a new version of the tool being used by those tasks that made them run almost twice as fast in certain cases. Those changes cut the time it takes to run a 3-year forecast from 3 days to 12 hours.
It’s far from a perfect solution. Celery will almost certainly need to be replaced when we upgrade to PSSE 34 or 35. Celery 3.1 only supports up to Python 3.4 and hasn’t been updated since 2018. Celery 4.0 dropped official support for Windows. In addition, once tasks have been sent to the broker they’re not easy to stop. Either the workers need to be restarted and the queue purged or all the tasks sent to the broker need to be revoked. If not, tasks will keep running until they finish. It is progress, though.
Loved the article? Hated it? Didn’t even read it?
We’d love to hear from you.




Thanks for simplifying Windows & Celery integration. Great read!