

If you’re reading this, you’ve probably heard about the vulnerability that was recently discovered in the log4j library. Or maybe this is a few years in the future, and yet another huge software vulnerability has been discovered, and someone passed this post to you in order to help explain what is going on.
Either way, you’re probably wondering what is happening in the software world that allows these critical undiscovered vulnerabilities to lie dormant for years, only to pop up and cause the entire technology world to collectively lose its mind.
I’m going to start at a pretty fundamental level to explain what is going on, so if you’re a software engineer, you probably won’t get much out of this. However, if you’re not in IT and you really want to understand what in the world is going on, you’re in the right place.
Really, what *is* software?
We all sorta know what software is. We know it runs on our computer. But what *is* it, really?
Well, everything that runs on your computer is software. The operating system that you login to when your computer starts up, the applications that you run such as Microsoft Word, the little pop-ups you get reminding you that you haven’t renewed your anti-virus software in 5 years. They are all software.
All of this software is just made up of a bunch of files that your computer knows what to do with. The Microsoft Word icon on your desktop is a special type of image file, the Word application itself is made up of a bunch of files, that image your friend sent you is a file. Everything is just a different type of file that your computer can interact with.
The only real difference between the Word icon on your desktop and an image that your friend sent you is that your computer knows that if you click on the Microsoft Word icon (which is a file), that it needs to start the Microsoft Word application.

At this level, that is all you need to know. Everything on your computer is made up of many hundreds of thousands of files. All different kinds. And your computer knows how to interact with most of them. Click on an image file, your computer opens up an application that works with images. Click on a link to a website, your computer will open up a web browser (what is a web browser?).
Files, all the way down.
This can get a bit more complicated though, because when you open up a web browser like Google Chrome or Microsoft Edge, you’re going to a website and you’re viewing data that was sent to your computer by another computer somewhere on the internet.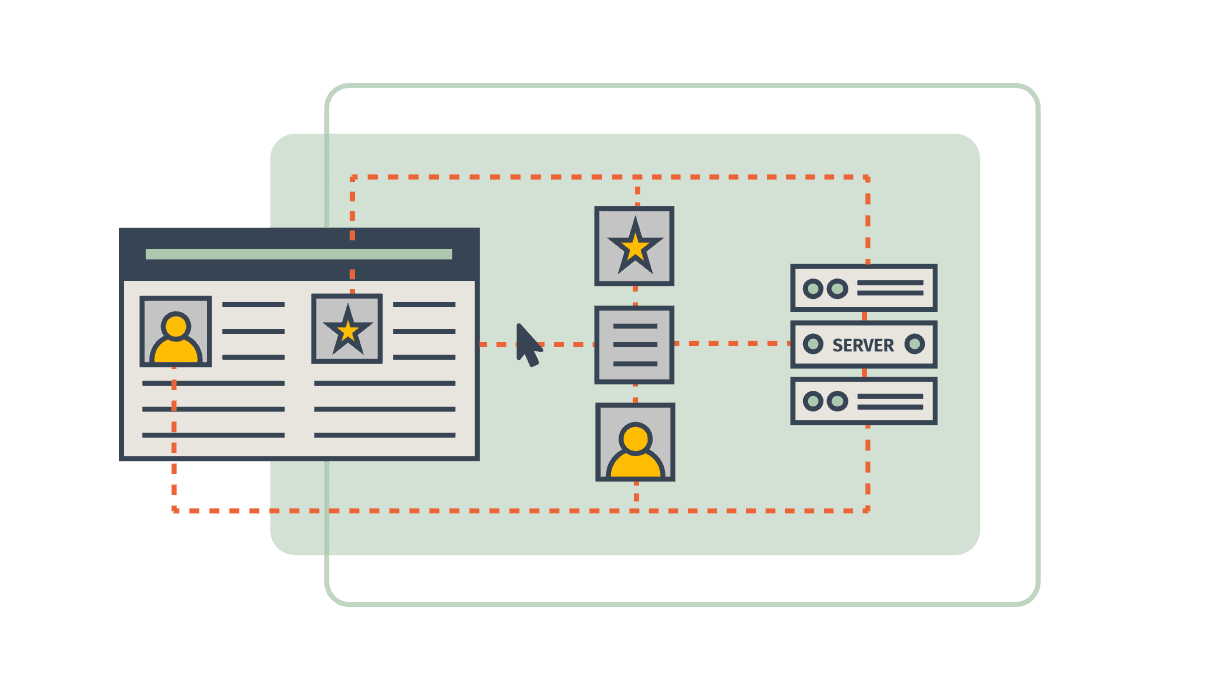
That other computer, called a server (What is a server?), is sitting somewhere else on the planet. When you typed in “www.google.com” a server over at Google sent you a bunch of files and your web browser used those files to display a web page to you. Pretty neat.
However, it is still just a bunch of files, only this time they were sent to you over the internet.
But what are these files made of?
Okay, so your computer is just a bunch of files. Great. But what is actually going into these files? That is a bit harder to explain, but I’ll give it a shot.
All software is written in what we call “programming languages”. A programming language is just a bunch of text that can be translated into a set of operations that your computer knows what to do with.
Here is a little snippet of what a programming language looks like:
import "fmt"
func main() {
fmt.Println("hello world")
}
This is what people usually refer to as “code”. It isn’t important what this piece of code does, just know that all software is just made up of a bunch of files that have reams of text like what you see above. And know that some person, somewhere, had to write all of that text.
In order to make that text into something a computer can use, there is a special program called a “compiler”. The compiler takes this text, and turns it into a bunch of instructions that your computer can run, and shoves those instructions into a file (or a bunch of files). So when you run an application like Google Chrome, your computer finds the “compiled” Chrome file, opens it, and starts performing each instruction.
That is really all your computer does, all day long. It just sits there opening up file after file, reading out instructions and running them one after another over and over and over. All day, every day.
I’m not really getting any closer to understanding security vulnerabilities.
I know, I know, bear with me. We are getting closer. So we have all of these special files on our computer that are full of a bunch of instructions created by “compilers”. And our computer just goes through these files executing the instructions. These instructions are really simple operations though, they aren’t complex things like “show the Chrome window to the user” it is simple instructions like “add these two numbers together” or “put a dot on the screen in this location”.
The instructions are actually even more fundamental than that, but I think you get the idea. These instructions are incredibly basic, and it takes a TON of these instructions for applications to do anything.
These instructions have to be really simple, because that way you can combine a ton of these instructions in different ways and cause your computer to do pretty much anything. If these instructions were complex like “draw a button on the screen”, then you’d need tons of very specific instructions to do anything. You’d need a “green button” instruction to draw a green button and a “red button” instruction to draw a red button. This would get out of hand quickly.
But instead, we have a bunch of incredibly basic instructions that we can string together to draw a red button or a green button. These very simple instructions would cause the computer to draw, pixel by pixel (what in the world is a pixel?), each piece of the button. Because we are using very simple instructions, we can combine them in an infinite number of ways to draw anything on the screen, including the letters you’re reading right now.

In order to produce all of these instructions, we need a lot of code. Your computer is pretty dumb, it just sits there all day running instructions. So the code we write needs to tell your computer every single thing it needs to do… in EXCRUCIATING detail.
For example, let’s look at the web browser example from earlier. You are typing in an address for www.google.com into your browser, what needs to happen in order for that to work? If I told you, you wouldn’t believe me. Many thousands of things. Everything from interpreting the keystrokes from your keyboard to drawing the letters on your screen to making requests across the internet to Google. But each of those actions is made up of many hundreds of thousands of very simple instructions.
Unreal, right? Don’t worry, programmers don’t really understand all of it either.
It is so complicated that it is hard to wrap your mind around it. And that is one of the big secrets that almost all software engineers share. Most of us are dumbfounded as to how it all works so well. It is unbelievably complicated. And nobody really understands all of it.
Is it starting to feel like a house of cards?
Now you know how software engineers feel.
You might be wondering at this point, if all of these millions of instructions are needed to accomplish really simple tasks, then how in the world does anything get done? I’m glad you asked, because now we are really starting to get somewhere. Software engineers don’t have to write all of the code that runs in their applications!
If software engineers had to write every line of code that went into modern applications, even the simplest of applications would take years to write. Even a team of software engineers would take years to write the simplest of applications.
The reason is that every application leverages code written by many thousands of other engineers. Thousands of engineers? Yep. As an example, applications leverage huge amounts of code that lives in your operating system (the application that runs your whole computer). That is the reason why applications that run on Windows all look very similar, and applications that run on MacOS all look very similar. Those applications are working with the operating system to draw things on the screen, connect to the internet, pop up notifications, etc…
The software that runs your computer, the operating system, is absolutely enormous. Windows 10 is roughly 50 million lines of code. 50 MILLION. So let’s say a novel has about 20 lines of text per page, we are talking about 2.5 million pages, or well over 11,000 copies of the first Harry Potter book.
That would be a pile of Harry Potter books reaching almost as high as the Eiffel Tower, or roughly 2/3rds of the way up the Empire State Building. And this isn’t just english text, this is detailed computer code that has been written and rewritten over and over by myriads of people.

Hard to believe, right?
And that is just the software that is part of Windows. Our applications need to accomplish a lot of tasks that other similar applications need to do too. Things like manipulating image files, displaying pdfs, displaying web pages, playing music, taking payments, etc… almost any broadly applicable functionality you can think of.
Applications share a lot of functionality between each other. And so programming languages use special files called “libraries”. These libraries are bundles of files that contain functionality that an application can use. Think of them like a toolbox for an application. Your application needs a hammer? Well, it isn’t worth it to build a hammer, we have a hammer in this library over here, let’s just use that one. Individual applications can leverage thousands of these libraries to perform all kinds of tasks. Software engineers pull in all of these libraries because why would you want to write all of this code, when someone else has already created it for you?
And so, in many applications, these libraries have a lot more code in them than the applications themselves.
To put that in perspective, let’s say that I have a relatively small application made up of about 50,000 lines of code that my team wrote. I might use external libraries that are made up of a few million lines of code, and then I’m running on top of an operating system made up of tens of millions of lines of code. Modern applications leverage a staggeringly large amount of external code.
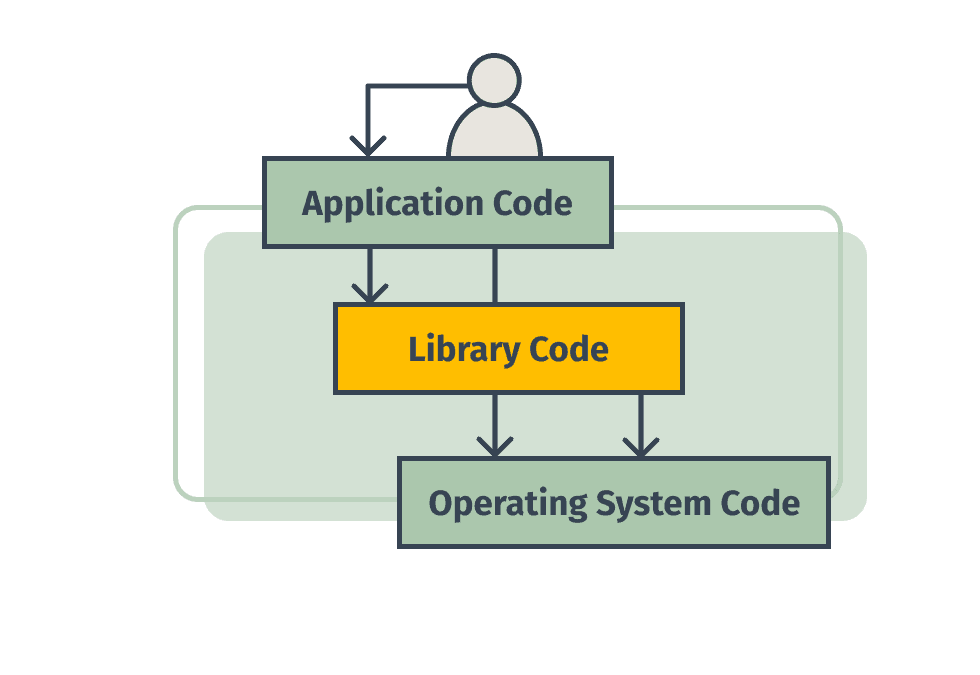
Security vulnerabilities can occur in any of this code.
We have finally arrived at security vulnerabilities
In all of these millions of lines of code, a security vulnerability can be lurking almost anywhere. But what do I really mean by a security vulnerability? Well, a security vulnerability is just some defect in the code that causes the code to do something it isn’t supposed to, in a way that allows an unauthorized person control of a system or access to data.
As an example, let’s say in one of those millions of lines of code, there is an instruction that a programmer wrote that says essentially “if the value coming from the user in this text field starts with ‘hacked:’ then take whatever is after that and treat it like an internet link.” So someone goes to your application, and types in “hacked:www.google.com” and it causes your application to see that text and it tries to access “www.google.com”.
That doesn’t sound so bad, unless the code is also supposed to take whatever is at that address and then try to do something else with it. Maybe the application is supposed to load whatever is at that location and then try to run it like it is part of the application? Then a user can type in “hacked:www.myevildomain.com” and get your application to load their malicious code into your application. If this application is running on a website such as Facebook, Google, Instagram, etc… then doing that could allow that attacker to run code that can give them access to the data stored there by other users. You now have a security breach on your hands.
But why would someone do that?
The above example is very contrived. Of course no programmer is going to purposefully provide a way for someone to load someone else’s code into their application. That is software security 101. But applications are doing things all of the time that require them to take some kind of data from a user, whether that is a piece of text from a form in a web browser, or an image that a user uploads. Applications take in a ton of data from users, and then they need to process it in some way.
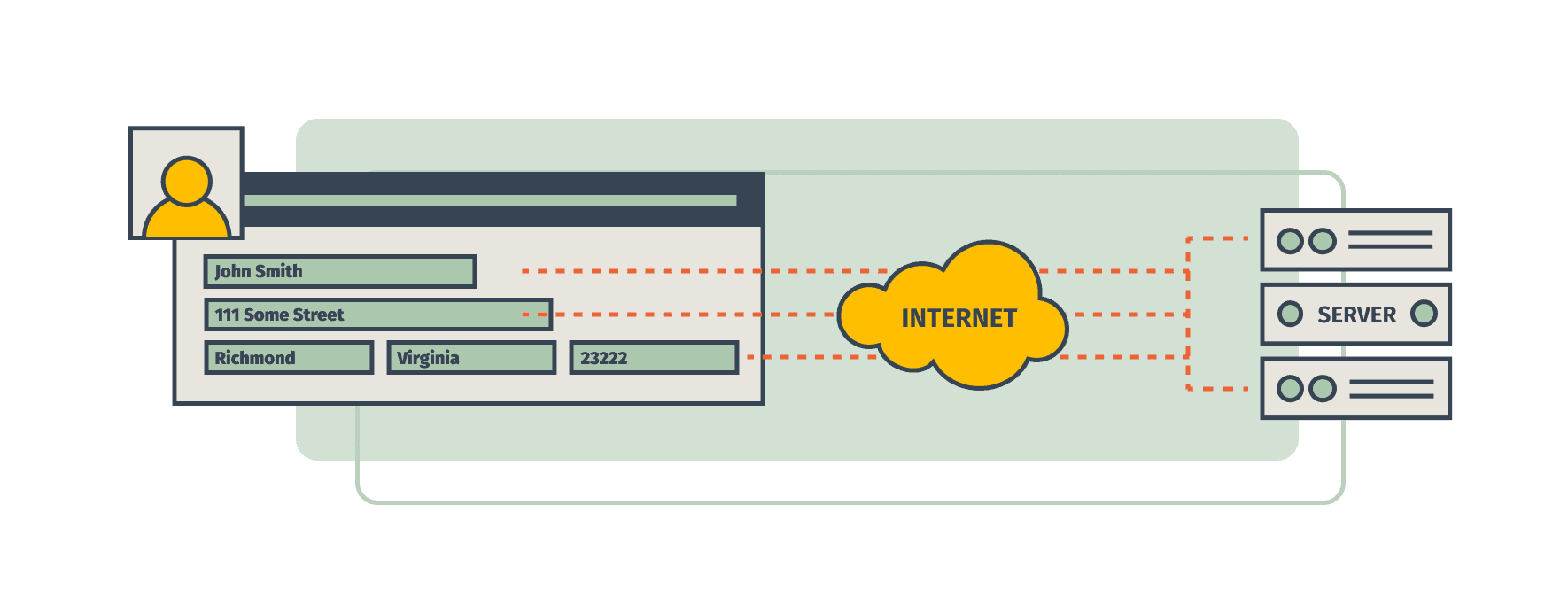
That is a lot of data to clean and make sure it is safe. By taking in and processing this data, it provides a lot of opportunities for a specially crafted piece of data to cause a program to operate in a way that the programmer didn’t intend. Let’s say that a hacker uploads a file to an image sharing service that looks like an image file, but instead is filled with some commands that the hacker wants to run.
The hacker knows that the website they are uploading this file to is using a specific library to process image uploads, and they know that the library looks at the start of the image file for a particular set of values and then will run some commands in response to those values, passing in the data from the image file. This kind of thing is done all of the time to process images uploaded to websites to resize them, or apply an overlay to the image, add a filter, etc… if the library isn’t incredibly careful about how it ensures the data from the image is valid, it can accidentally execute commands that the hacker passed to it. Some variation of this has been the source of many security vulnerabilities in the past.
And at its core, this is really the source of most software security vulnerabilities. Taking in data from users… images, files, text… and being tricked into doing something inappropriate with it. Because of the fact that there are so many millions of lines of code being used by most applications, it is impossible to audit all of it and look for every possible type of defect.
The only reason these flaws aren’t found more often is because most applications have pretty good security practices baked into them, and most libraries have a lot of people looking at the code. But every so often a subtle bug finds its way into a library that goes unnoticed for years because it is something that is very rarely used… and that is what happened with log4j.
But what about log4j
The log4j vulnerability was very similar to the website example that I described above. The log4j library is used in applications for writing information out to log files. Log files are files that record everything an application does and are used to troubleshoot issues that arise. A log file might look something like this:
06:42:16.423Z INFO cool_app: start
06:42:16.427Z INFO cool_app: responding to request from 52.38.16.32 path /hello
06:42:16.433Z INFO cool_app: responding to request from 12.22.18.45 path /whatever
06:42:16.438Z INFO cool_app: something weird happened
Log4j had a feature in it that allowed a special piece of text to be placed in a log message that would cause the library to do something special with that text. If text was wrapped with “${}” then the library would do something special with it. It might look something like this:
“${my_value}”
This allows a developer to insert a special value into a log message and it would do something with that value and replace it. Here is an example:
“${date:MM-dd-yyyy} - My Log Message”
Then this would actually get written into the log file:
09-12-2021 - My Log Message
This is really useful functionality. It allows you to automatically replace values in your log message without knowing the values up-front. These replacements could be used in combination with another piece of functionality called JNDI that actually came from a different library. JNDI allows you to look up values in a variety of ways, some of them allowing you to make requests over the network or internet to get a value. That could look something like this:
“${jndi:ldap://www.mywebsite.com/somepath}”
This would make a call out to “ldap://www.mywebsite.com/somepath” and could even try to run code that came back from it. This could be useful functionality, but these substitutions should always occur only on text provided by the application, never by the user. Log4j had, for a long time, allowed these substitutions to occur in any user-provided text that might make it into the logs.
So all a user had to do was to perform an action against a website that might cause a value to be written into the logs, and they could get this functionality to run. Because this was such a minor feature in a large library (log4j has over 175,000 lines of code spread across over 2000 files), this went unnoticed for a really long time. (Why a library that writes logs to files is over 175,000 lines of code is unfortunately a discussion for another time.)
Now you know the software industry’s dirty little secret
Software is unbelievably complex and is built upon millions of lines of code, and no one has the ability to audit all of that code. Software engineers rely on popular libraries like log4j, because it would take them inordinate amounts of time to replicate that kind of functionality on their own. Software engineers also like to use libraries like log4j because they are used by millions of other developers, and so having that much usage and that many eyes on a piece of software can help find and flush out many of the security issues.
However, every once in a while something like this happens. You have a very widely used library, combined with a rarely used feature that has a subtle flaw in it, and that flaw can go unnoticed for years. Inevitably people will now go scouring other libraries that are similar to log4j, looking for bugs like this elsewhere, and will probably find a few.
There are tons of other security flaws like this, sitting out in the wild just waiting to be found. The software engineer community has created a program called CVE which stands for Common Vulnerabilities and Exposures. It is a warning system for software engineers to alert them of flaws found in the libraries they are using to write software.
Even a security flaw that is fairly minor will get issued a CVE number, and will be reported through tooling that most software engineers use. This way, software engineers can know when they need to update their libraries in order to keep their users safe.
Loved the article? Hated it? Didn’t even read it?
We’d love to hear from you.




Thank you for the very informative article. I like your gentle buildup approach.