

(At the end we break this down for LINQ to SQL, so stay tuned in!)
In SQL server programming (and set theory) a Union combines all rows from two result sets. In SQL programming these two result sets must have the same number and type of columns. While these two operations perform very similar tasks, their performance can be quite different. So, to demonstrate a UNION we will use this query from the AdventureWorks database. This query has two sub-queries looking for different strings in the product number column. The strings are very similar and will likely have overlapping columns, but the UNION operation will filter these out. Lets, look at an example…
SELECT [ProductID], [Name], [ProductNumber] FROM
Production.Product WHERE ProductNumber LIKE '%BE-%'
UNION
SELECT [ProductID], [Name], [ProductNumber] FROM
Production.Product WHERE ProductNumber LIKE '%BE%'
This query will yield these results…
| ProductId | Name | ProductNumber |
| 3 | BB Ball Bearing | BE-2349 |
| 4 | Headset Ball Bearings | BE-2908 |
The same query with a UNION ALL instead of UNION will in turn yield these results…
| ProductId | Name | ProductNumber |
| 3 | BB Ball Bearing | BE-2349 |
| 4 | Headset Ball Bearings | BE-2908 |
| 3 | BB Ball Bearing | BE-2349 |
| 4 | Headset Ball Bearings | BE-2908 |
The real difference comes in though when you look at the query plans. The UNION operator has this query plan…
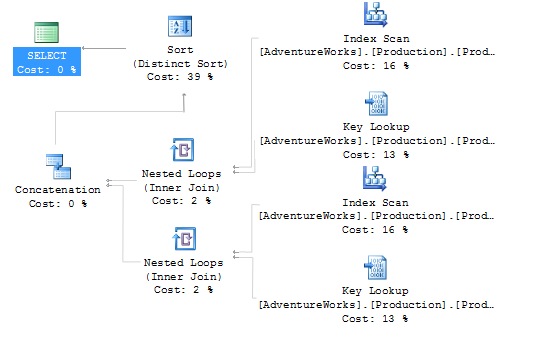
And the UNION ALL has this query plan…
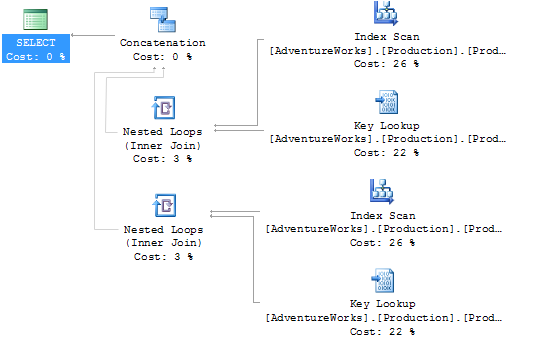
Notice the missing "Sort (Distinct Sort)", this is the step that removes all of the duplicate rows after the sets have been concatenated. While this may not seem like much, you'll notice that the cost on this step is 39% in this query! That means that we are doing almost twice the work, just to remove two duplicate rows. While in this very small query this doesn't add up to much, but if the result set was increased in size dramatically you could see some serious performance degradation.
And just so you know, the query optimizer *is* smart enough to figure out sometimes whether or not two sets will have any potential overlap. So, if we had a query that looked like this…
SELECT [ProductID], [Name], [ProductNumber] FROM
Production.Product WHERE ProductNumber LIKE 'BE%'
UNION
SELECT [ProductID], [Name], [ProductNumber] FROM
Production.Product WHERE ProductNumber LIKE 'BF%'
The query optimizer knows that two sets, one starting with BE and one starting with BF could not overlap in any way and so the execution plan that SQL Server generates for this query is identical to the one that it would generate for the UNION ALL variation of it. But in your queries, especially if you have very complicated ones, SQL Server may not be able to determine if there will be duplicates and so it will have to put in the extra effort to filter out duplicates. If you know that your query won't be affected by duplicate results then you can experience some nice performance benefits by switching to the UNION ALL statement.
In the SQL 99 syntax UNION DISTINCT was added and it is exactly the same as UNION, it was just put in so that you could explicitly state your intention when you execute a UNION. It would have been much easier if we were forced to use either UNION ALL or UNION DISTINCT, thereby causing us to think about which UNION we want before we use it, but SQL Server doesn't even support the UNION DISTINCT syntax.
In LINQ to SQL things operate a little bit differently. If we wanted to do the same query using UNION we would write the query to look like this.
(from p in Products where p.ProductNumber.Contains("BE")
select new { p.ProductID, p.Name, p.ProductNumber })
.Union(from p in Products where p.ProductNumber.Contains("BF")
select new { p.ProductID, p.Name, p.ProductNumber })
The SQL generated is basically the same as what we wrote, only wrapped in a select that will likely be optimized away by the SQL server query optimizer.
SELECT [t2].[ProductID], [t2].[Name], [t2].[ProductNumber]
FROM (
SELECT [t0].[ProductID], [t0].[Name], [t0].[ProductNumber]
FROM [Production].[Product] AS [t0]
WHERE [t0].[ProductNumber] LIKE '%BE%'
UNION
SELECT [t1].[ProductID], [t1].[Name], [t1].[ProductNumber]
FROM [Production].[Product] AS [t1]
WHERE [t1].[ProductNumber] LIKE '%BF%'
) AS [t2]
If we want a UNION ALL though you might look around for one, but you will quickly find out that one does not exists. The method you are looking for is Concat, and you use it the same as Union.
(from p in Products where p.ProductNumber.Contains("BE")
select new { p.ProductID, p.Name, p.ProductNumber })
.Concat(from p in Products where p.ProductNumber.Contains("BF")
select new { p.ProductID, p.Name, p.ProductNumber })
It produces identical code to Union with the exception that in SQL server it uses a UNION ALL instead of a UNION. The reason that this was done this way was because these operators work everywhere, not just in LINQ to SQL. In set theory a UNION is the combination of all items in two sets, and so there are no duplicates. Concat simply joins two sets together and is actually more semantically correct than UNION ALL.
So there you have it. When writing SQL always consider whether UNION ALL will fit your problem, because it could save you a few processor cycles on your DB. And when writing in LINQ consider whether a Concat will serve your purpose better than a Union because it doesn't really matter which Linq provider you are using, a Union is almost always going to require filtering duplicates, and therefore will be slower.
Loved the article? Hated it? Didn’t even read it?
We’d love to hear from you.



