
One thing I absolutely love about Remix‘s loader and action functions is that they implement the web fetch Request / Response model. That means integration testing with Remix can* feel as fast and easy as writing unit tests for any other JS function:
it("Create a new todo item", async () => {
// Setup the formData object the action is expecting
const formData = new FormData();
formData.append("title", "New todo");
// Run the route action function
const response: Response = await action({
request: new Request(`/todo`, { method: "POST", body: formData }),
params: {},
context: {}
})
expect(response.status).toBe(200) // Expect OK response code
const todos = await db.todo.findMany();
expect(todos.length).toEqual(1) // Expect a single Todo record
})
*However, setting up this type of testing experience so that it’s predictable and isolated takes a little bit of work. So, in this post, I’m going to walk you through a robust pattern for integration testing with Remix, Prisma, and Vitest.
TLDR;
The rest of this article will show you how to do the following:
- Spin up two separate databases (dev + test) with a single
docker-compose.yml - Use
dotenv-cliand a.env.testto run Prisma and Vitest with the test database - Use Prisma’s
db.$queryRawcommand to quickly truncate the database between tests
We also have an example Remix project available on GitHub that uses this system and contains all of the code below. Alright, let’s get started…
Composing the databases.
I love using Docker Compose when working with Postgres or MySQL locally. It makes managing multiple versions and instances across my projects so much easier. However, working with multiple databases within the same project can be tricky since the pre-defined postgres* docker image doesn’t support a way of doing this at runtime (buildtime? starttime? I’m not a docker expert haha).
To get around this, we run a bash script that creates multiple databases inside the container on startup. That bash script is shamelessly taken from mrts on GitHub and looks like this:
#!/bin/bash
set -e
set -u
function create_user_and_database() {
local database=$1
echo " Creating user and database '$database'"
psql -v ON_ERROR_STOP=1 --username "$POSTGRES_USER" <<-EOSQL
CREATE USER $database;
CREATE DATABASE $database;
GRANT ALL PRIVILEGES ON DATABASE $database TO $database;
EOSQL
}
if [ -n "$POSTGRES_DATABASES" ]; then
echo "Multiple database creation requested: $POSTGRES_DATABASES"
for db in $(echo $POSTGRES_DATABASES | tr ',' ' '); do
create_user_and_database $db
done
echo "Multiple databases created"
fi
Then, in our docker-compose.yml we map the directory our bash script is in to the docker-entrypoint-initdb.d directory. In my case, I keep it in ./scripts/pg-init.
version: "3.7"
services:
postgres:
image: postgres:latest
restart: always
environment:
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=postgres
- POSTGRES_DATABASES=dev,test
ports:
- "5432:5432"
volumes:
- ./scripts/pg-init:/docker-entrypoint-initdb.d
Notice how we also set our new POSTGRES_DATABASES environment variable that our script is listening for to dev,test to create two databases.
Now, when we run docker-compose up, we see output notifying us that we created two databases within the container. Yay!
postgres_1 | Multiple database creation requested: dev,test
postgres_1 | Creating user and database 'dev'
postgres_1 | CREATE ROLE
postgres_1 | CREATE DATABASE
postgres_1 | GRANT
postgres_1 | Creating user and database 'test'
postgres_1 | CREATE ROLE
postgres_1 | CREATE DATABASE
postgres_1 | GRANT
postgres_1 | Multiple databases created
Use the test database with Prisma, Vitest and dotenv-cli
Now that we have our new test database, we need to keep its schema in sync with our development schema and change our DATABASE_URL environment variable when we run Vitest. Thankfully, with Prisma, npm script aliasing, and dotenv-cli – that’s easy.
Setting up our .env.test
dotenv-cli is a tool that allows us to specify custom .env files when running CLI commands. For our purposes, we’re going to use it to change our DATABASE_URL so that Prisma links to our test database when running our tests inside Vitest.
To make that happen, simply make a copy of your .env file called .env.test and change the last slash in your DATABASE_URL to the name of your test database. It should look something like this:
DATABASE_URL="postgresql://postgres:postgres@localhost:5432/test"
Syncing our schemas
Before running our tests, we always want to make sure our test database’s schema is up-to-date. Prisma makes this easy with the npx prisma db push command.
Running this will match our database to the end state of our migrations – without running each migration individually. This makes the process of spinning up our database incredibly fast, and adding the --accept-data-loss flag means that if Prisma runs into conflicts with the records in the database, it will delete them automatically (which is fine because we’re going to truncate our database before testing anyway).
So, combining this command with dotenv-cli we get the following command:
dotenv -e .env.test -- npx prisma db push --accept-data-loss
Running our tests
Similarly, we can run our tests with Vitest now by specifying the the environment before we start the runner:
dotenv -e .env.test -- vitest
Now our test environment is isolated from our development database – cool! But we’re not done. We still have to work on…
Isolating our tests from each other.
Truly running our integration tests in isolation means making sure we clear the database in-between tests.
Sadly, Prisma doesn’t have a built in method for truncation, and running npx prisma migrate reset --force would be way too expensive to do before every test. Luckily, we can use the db.$queryRaw directive to easily make our own truncateDB function:
import { db } from "~/db.server"; // db is the prisma client
export async function truncateDB() {
const tablenames = await db.$queryRaw<
Array<{ tablename: string }>
>`SELECT tablename FROM pg_tables WHERE schemaname='public'`;
for (const { tablename } of tablenames) {
if (tablename !== "_prisma_migrations") {
try {
await db.$executeRawUnsafe(
`TRUNCATE TABLE "public"."${tablename}" CASCADE;`
);
} catch (error) {
console.log({ error });
}
}
}
}
Then, in our test file, we can tell Vitest to truncate the database before each test:
beforeEach(async () => {
await truncateDB();
});
Easy. But wait…
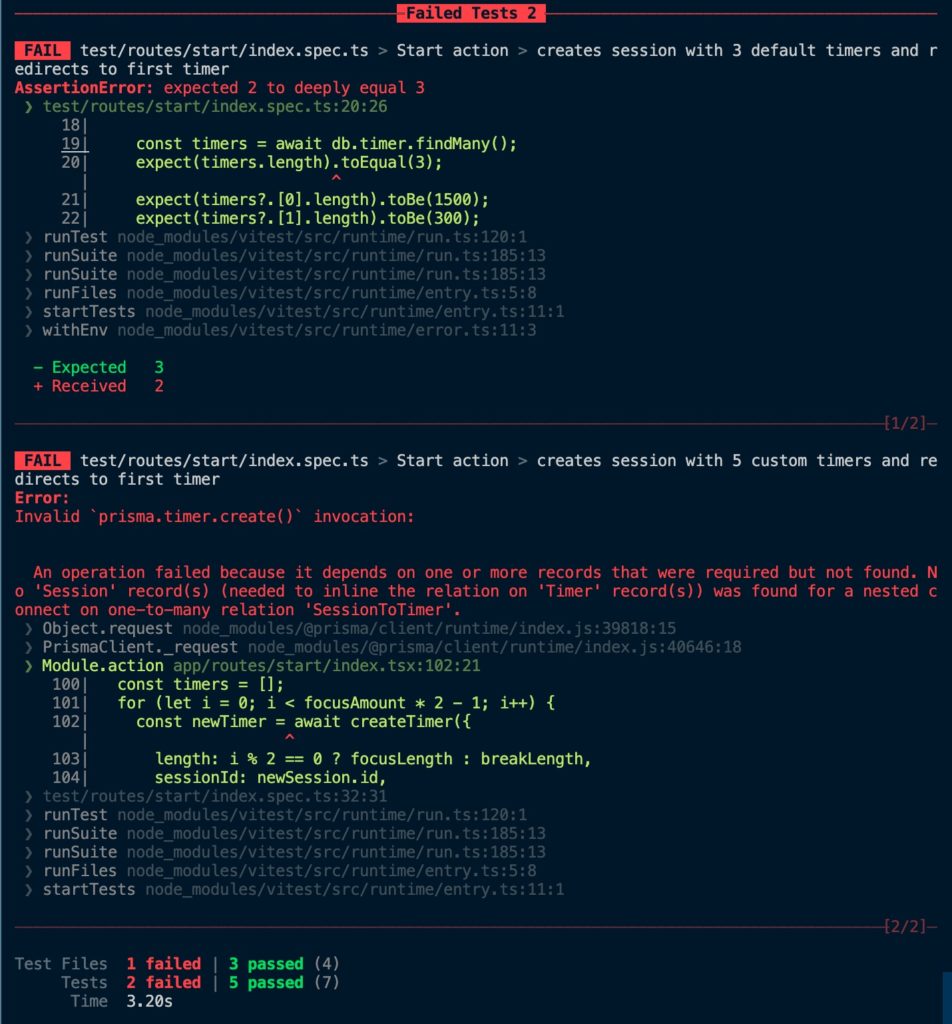
Why are our tests failing?
There’s one “gotcha” when using Vitest for this type of integration testing. Vitest runs test suites in parallel by default. By running a beforeEach that truncates our database, we’ve introduced a race condition where the truncation from one test can happen while another is running.
Luckily, there is a flag to turn off parallel test running, --no-threads. Adding that fixes the race condition issue and makes all of our tests go green (while still benefitting from most of Vitest’s speed enhancements):

Tying it together with script aliasing
Obviously, remembering all of these commands, flags, and processes is a pain. So, let’s improve our development workflow by adding some custom scripts to our package.json.
By adding the following db scripts, running migrations is as easy as npm run db:migrate:
"db:migrate": "run-p db:migrate:*",
"db:migrate:dev": "npx prisma migrate dev",
"db:migrate:test": "dotenv -e .env.test -- npx prisma db push --accept-data-loss",
run-p allows us to run scripts in parallel and db:migrate:* tells npm to run all scripts that start with the db:migrate: prefix. This makes sure that everytime we migrate our development database, the new schema is pushed to our test database.
Now, we can update our npm run test alias by doing the following:
"test": "run-s db:migrate:test test:unit",
"test:unit": "dotenv -e .env.test -- vitest --no-threads",
Now, we don’t have to remember to migrate our test database before starting our tests and we never have to think about our dotenv configuration again!
Did you notice anything?
I’m sure the primarily front-end developers did. We just set up an integration testing workflow without mocking a single function (let alone our entire Prisma client).
That’s because of Remix – which we didn’t have to configure at all to make this work. Since Remix is a fullstack runtime, we can use Prisma directly inside our loaders and actions. And by creating an isolated database, we can write true integration tests that don’t have to mock calls to a separate backend.
With Remix, you’ll never get mocked by your mocks, again.
Wrapping up
I hope this testing setup helps you build great websites with Remix! And don’t forget that all of the code in this article is available on GitHub.
If you have any thoughts, questions, or suggestions, comment below or mention us on Twitter @simple_thread.
* This article uses Postgres, but the same general process will work for MySQL.
Loved the article? Hated it? Didn’t even read it?
We’d love to hear from you.



Awesome setup. thanks!
I just changed the scripts to:
“test”: “run-s test:*”,
“test:unit”: “dotenv -e .env.test — vitest”,
“test:integration”: “npm run db:migrate:test && dotenv -e .env.test — vitest integration –no-threads”,
and named the files containing those integrations tests in *.integration.test.ts
that way I can run only the integration tests and not curry their burden when running unit tests.
Do you have a better way to do that?
This is great, thank you!!! Appreciate not having to worry about mocking anything and setting up that extra mocking configuration.
Truncating every single table is very slow in postgres. Rollbacks are much better.
Any idea on how you would implement a rollback strategy with vitest?