

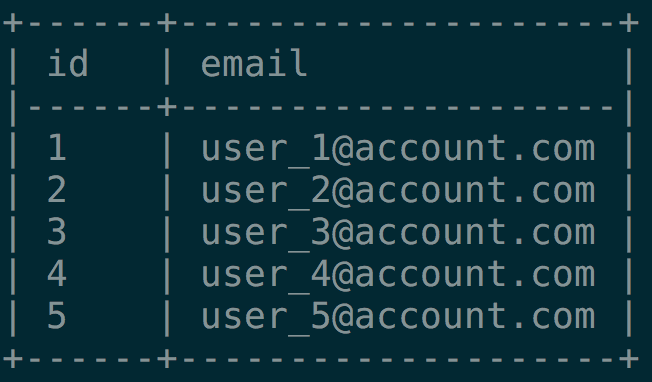
Given this table, which row will the following query return?
SELECT * FROM users LIMIT 1;
First one? Last one? Dig in your RDBMS documentation long enough and you’ll find a statement like this…
“If ORDER BY is not given, the rows are returned in whatever order the system finds fastest to produce”
In reality the returned results are usually insert order but that is not guaranteed. The frequency is high enough to fool you during development but that lack of guarantee can cause real bugs when you ship to production.
Core SQL Server architect, Conor Cunningham equates depending on query order without an ORDER BY clause to driving a car without a seatbelt. He even goes on to provide a reproducible example that spits out results in an “unexpected” order using a SELECT statement without the corresponding ORDER BY.
How Can We Find Order Dependent Queries?
The tricky part in a fairly complex application is ensuring you’ve done just that. You may generate thousands of unique queries and some of them are order dependent. What happens when one inevitably slips through without ORDER BY?
Obviously users will encounter rows of data moving around seemingly at random. Depending on your application this could range from annoying to catastrophic. (Imagine showing data points in a jumbled order for a stock ticker)
The more sinister bug is when you intend to lookup a single result and you’re oh-so-sure that multi-column WHERE clause will narrow the results down to a single row. Oh wait, turns out you were wrong but you’ll never be the wiser until the query optimizer decides maybe those other rows want a turn in the spotlight.
Also just because you have an ORDER BY statement doesn’t mean you won’t have ties. You might order by that datetime column but what happens when two rows get inserted within the same second? For those rows with ties you’re back to square one, leaving which row appears first up to the query optimizer.
Exaggerating Randomness
To help surface these issues during development I propose exaggerating the randomness of results in queries missing an ORDER BY. If you don’t care about order then let’s lose the pretense of getting results in insert order usually. Instead you get a randomized order. Doing this on development/testing databases will help ensure that if ambiguous sort bugs exist, developers are likely to see them.
If you squint, you’ll see this concept has parallels to Chaos Engineering. We want to intentionally wreck weak assumptions in a controlled manner.
I accomplished this with the following hack for PostgreSQL. It will do a one time scramble of data order physically.
This script iterates through all the tables and adds a column _rand which we’ll use to create an index. Clustering a table on that index causes the behavior we’re looking for.
SELECT id, email FROM users;
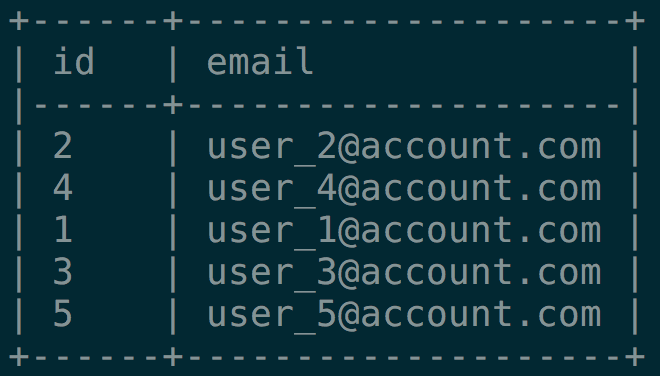
Maintaining Randomness
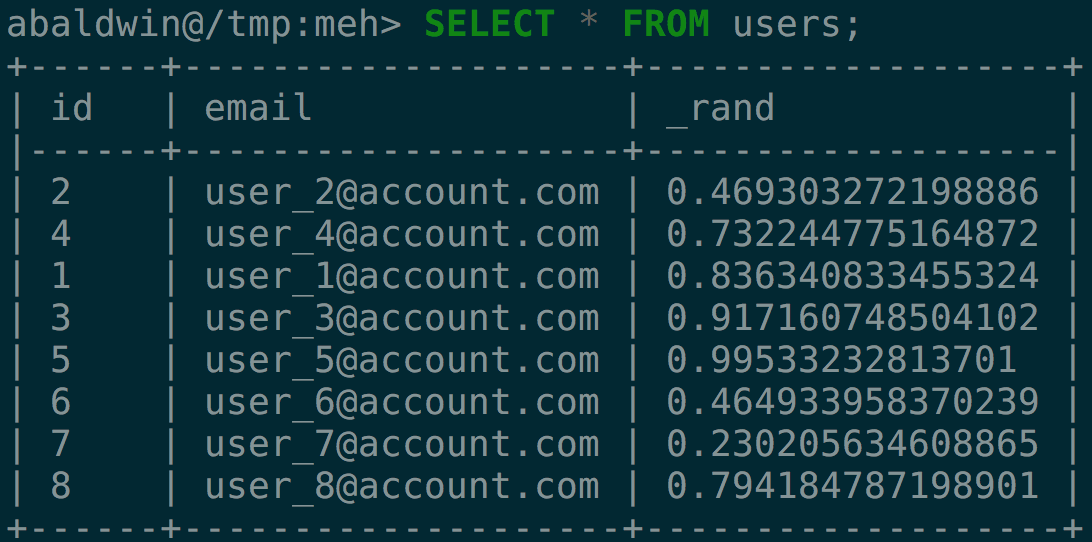
After running this against your development database you can poke around and look for buggy behavior. The catch though is that newly inserted data won’t be affected.
INSERT INTO users (email) VALUES ('user_6@account.com')
INSERT INTO users (email) VALUES ('user_7@account.com')
INSERT INTO users (email) VALUES ('user_8@account.com')
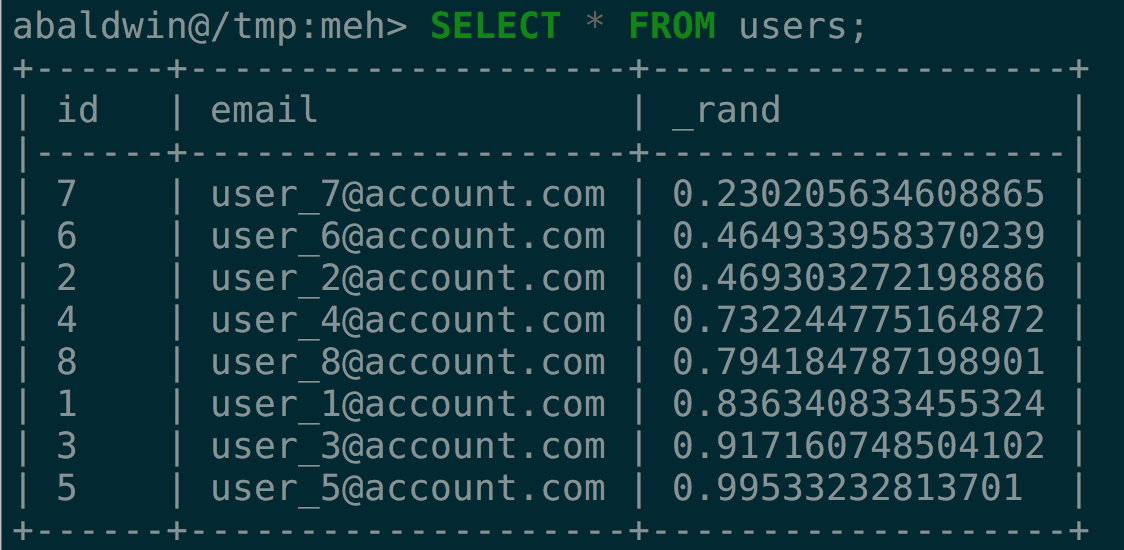
To fix this we need to run CLUSTER after new data has been inserted. We can run it against a specific table with CLUSTER users or against all tables with CLUSTER.
So periodically you must CLUSTER. One option is hooking into your ORM or testing framework hooks to run CLUSTER after new rows are inserted. Here’s how to accomplish this in Rails:
By adding the callback combined with the Postgres snippet in a migration I was able to run against test suites here at Simple Thread and surface real issues. This method still feels a bit hacky so if you have a better way to accomplish this I’d love to hear it!
Conclusion
Rico Mariani says we should architect our system in a way that creates a pit of success. When it comes to writing long queries in a complex system it seems all too easy to miss an ORDER BY when you need it. The least we can do is ensure rare behavior bubbles its way to the surface for developers during testing to see on a regular basis.
Loved the article? Hated it? Didn’t even read it?
We’d love to hear from you.



