

Why does it take so long to build software? We hear variations of this question frequently: Why is building software so expensive? Why is my team delivering software so slowly? Why am I perpetually behind schedule with my software?
There is a good reason we hear these questions over and over. Businesses need more and more custom software every day in order to stay competitive, and yet it feels like as time passes the speed at which we are delivering software is stagnating, or worse, getting slower.
I’d like to talk to you all about why this is, but in order to explore the topic, I need to introduce you to a topic that is near and dear to my heart: Essential complexity and accidental complexity.
Different types of complexity? That’s complex.
Any time you’re solving a problem, not just software problems, there are two types of complexity:
- Essential complexity – This is the complexity that is wrapped up in the problem. You can’t solve the problem without tackling this complexity. This is also sometimes referred to as inherent complexity.
- Accidental complexity – This is the complexity that comes along with the approach and tools that you use to solve a problem. This complexity isn’t part of the actual problem you’re solving, this is the complexity that you bring in with your solution. This is sometimes referred to as incidental complexity.
This idea was introduced to us by Fred Brooks’ seminal paper “No Silver Bullet – Essence and Accident in Software Engineering”. Think of it like this, if you’re trying to solve a math problem, the essential complexity is the understanding of math required in order to actually calculate a solution. If you want to solve the problem, you’ll have to learn the math required (or find someone who knows it). You can’t escape the math if you want to solve the problem.

Here comes the accidental complexity.
Let’s pretend that this is a challenging math problem, and doing it all in your head would be really unproductive. In that case, you’ll want to use a calculator. This is the accidental complexity. Remember the first time you tried to use a graphing calculator for something more than basic math? The accidental complexity is learning how to use that silly TI-83 to enter in all of the complex math to help you solve your problem. You didn’t need to use a calculator, but you knew it would help, and probably wouldn’t be too hard to learn.
But let’s pretend for a minute that you are familiar with Mathematica. Mathematica is an incredibly powerful and complex piece of software, but since you already know it, you decide to solve your problem using it. You’ve already made the investment in learning Mathematica, so it wasn’t a ton of extra effort for you, but you’ve just increased the accidental complexity of your solution by an astronomical amount.
A few weeks later a colleague of yours is in a similar situation, and remembers that you solved a very similar problem. They come to you to see how you solved the problem and you send them the Mathematica project. What do you think will happen at this point? Do you think they will learn Mathematica? Nope. They are going to figure out a different way to solve the problem, or try to make you solve it for them.
As you can see, these two kinds of complexity come from different places, but they are inextricably linked. You can’t solve a problem without some accidental complexity. Even a pencil and paper brings along some miniscule amount of accidental complexity.
You can’t solve a problem without some accidental complexity.
How does this apply to software?
This may come as a surprise to you, but the real revolution in software over the last 20 years has been the drastic reduction in the ratio of essential to accidental complexity. DHH used the term “conceptual compression” to describe this force and how it has changed our industry for the better. The proliferation of open source frameworks and libraries has been the most powerful force for reducing the amount of accidental complexity in software systems over the last two decades.
The amount of code required to solve business problems versus 20 years ago has been reduced by an order of magnitude, and so you would think that creating software would be an order of magnitude faster than it was back then. That doesn’t seem to be happening though, so why not? What is happening?
Software has steadily become easier to create, but while that has been happening, other phenomenon have been occurring concurrently:
- We are asking more and more of our software.
- The volume of software within companies is exploding.
- The pace of new technology adoption is increasing.
We are asking more and more of our software.
Even though we are leveraging more and more external tools and libraries to create our software, which should make creating software easier, we are constantly demanding more and more from our software. This alone has offset a huge amount of the gains. If we were still trying to build 2000 era web applications with modern tools, we actually would be seeing tenfold (or more) increases in the productivity of software construction.
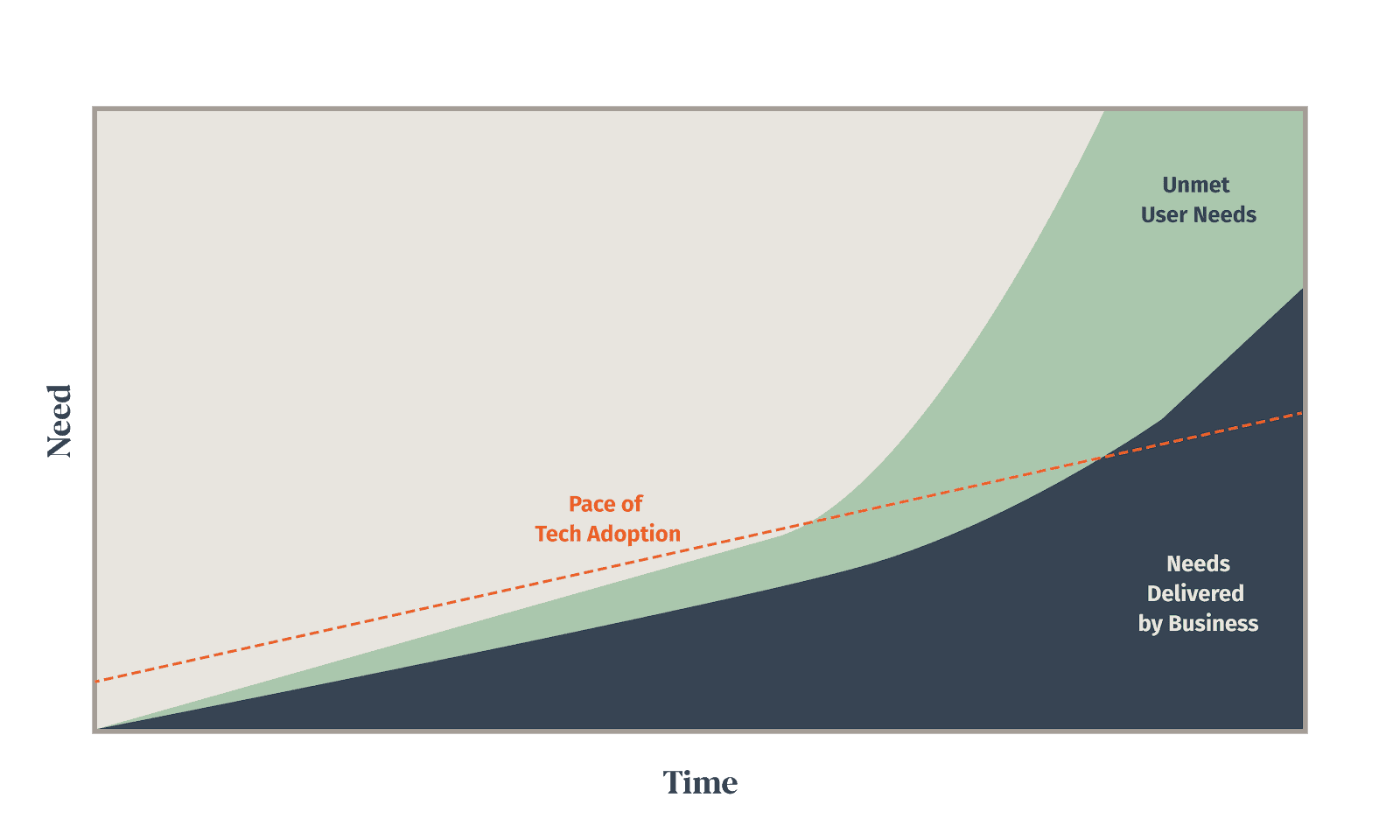
But things don’t stand still, and what both consumers and businesses expect from software has been increasing rapidly. We expect software to do so much more than we did 20 years ago. And as we build these larger and more feature rich applications, in order to keep them reliable, functional, and understandable we have had to change the way we build software.
Here are just a few examples of the changes that we’ve seen across the industry over the last two decades:
- Source control – Source control has been around this whole time, but it hasn’t always been as universal as it is now. Don’t think this adds accidental complexity? Go ask a junior engineer using Git for the first time what they think.
- Automated Testing – We have introduced a lot of testing and testing tools. We do acceptance testing, integration testing, unit testing, etc… This adds a significant amount of accidental complexity to the project, but at the benefit of ensuring that the software delivered is high quality and functions as expected.
- Splitting it up – As a system grows in complexity, the number of possible connections and interactions between components grows quadratically. This means that at some point, if software isn’t well designed, these interactions will continue to grow until the software sags under its own complexity. Breaking systems apart, especially if distributed over a network, brings along an enormous amount of accidental complexity.
- Specialization – As web applications have become more complicated, we have started to introduce a lot of specialization. Whereas in 2000 it wasn’t uncommon at all for a software engineer to design the UI, build the UI, and build the backend of an application, in 2020 this is now a handful of roles. Often a team building a web application will consist of a UI designer, UX designer, frontend software engineer, backend software engineer, and DevOps engineer. In larger orgs you’ll mix in folks with even more specializations around security, architecture, data management, data science, etc… All of these extra roles allow us to build software at a larger scale, but the tools and processes required to orchestrate teams like these introduce a huge amount of accidental complexity.
- Infrastructure automation – To build larger and more complex environments to operate a growing number of applications we have begun to automate their creation and maintenance. This allows us to more easily manage environments at scale, but pulls in a whole suite of tools and knowledge needed to do this effectively. The amount of complexity brought in by some of these tools can be immense, leading to DevOps becoming a dedicated role on most large teams.
- Frequent deployments – Because applications are growing in size and complexity, we need to deliver in smaller increments to reduce risk. In order to accomplish this we have introduced the concepts of continuous integration and continuous deployments. Again, this is wonderful for delivering software at scale, but it brings accidental complexity from the myriad of tools and skills needed to build and operate these pipelines.
- Multiple devices and form factors – We used to be able to say that our software was being used on a handful of known resolutions inside of a single operating system. Now our applications need to run on desktop, laptops, and mobile devices across a huge number of platforms. Often we will have native mobile applications as well as web applications. Maybe throw in some IoT applications and watch applications while you’re at it. This allows us an enormous amount of flexibility in where and how we access our data, and is a change that has transformed our society, but undoubtedly added complexity to the software construction process.
The volume of software within companies is exploding.
Even before reading the section above, you probably had a pretty good idea of how demanding more from our software and building in multiple form factors can lead to increasing complexity. But on an individual application basis, how does having more software within an enterprise increase the complexity of building out a single application?
The answer is straightforward. It doesn’t, except when you want that software to interact with other software. The more software that exists within a company, the more overlap between systems there is, which means that different systems need access to the same data in order to function. This means even more systems to store the shared data, and integrations between all of them.
As an example, let’s say you’re an office chair manufacturer in 2000 and you don’t have a web presence yet. You need to build an inventory system for your company and so you work to build out software to do just that. That inventory system is used by the folks in the warehouse, and you can run nightly reports to get inventory levels and those reports can be sent to folks throughout your company. The system is relatively standalone, and everyone is okay with nightly reports. Things just don’t move very quickly.
Fast forward to 2020 and your inventory system is far from standalone. You have partners that can push orders directly into your systems, you have a web storefront that gets real-time inventory updates and updates inventory as orders are placed. Your inventory system is integrated directly with your shipper so that you can automatically generate shipping labels and schedule pickups. You sell your products directly on Amazon and so your inventory system is integrated directly with the third party software that manages that process. The folks in your warehouse are using mobile devices to locate, scan, check-in, and pick inventory, so you probably have a mobile solution to manage all of that.
As systems proliferate, and take over all aspects of business operations, they start to overlap more and more until nothing can fulfill its needs without integrating with a dozen other systems. While this has provided an unprecedented amount of productivity and automation, it has introduced a significant amount of, you guessed it, accidental complexity around all of the data movement and integrations.
Marc Andreesen famously coined the phrase “software is eating the world”, this process is accelerating with no end in sight.
The pace of new technology adoption is increasing.
Back in 2000 you generally bought your platform from a single vendor such as Microsoft, Sun, or Borland and you might buy a few components, but you had your entire ecosystem from a single vendor. You were limited in what you could accomplish by what your vendor supported, but the amount of external tools and technologies you were adopting and integrating was relatively small.
In order to keep up with the rapid changing technology landscape, companies started to adopt more open technologies that evolve at a rapid clip. This came with huge advantages, allowing you to accomplish feats with these tools that you could only have dreamed of previously. But switching tools frequently comes with a cost, you end up introducing a lot of accidental complexity into the process.
While using a bleeding edge tool might give you performance in some areas, the newer it is, the more you’re going to feel the pain of supporting it. Also, the earlier you adopt a technology, the more pain you’ll experience as it grows and matures into a tool that is useful to a wide swath of users. Balancing the gain of leveraging a new technology with the pain that comes along with its use is something that technologists have been struggling with for a very long time.
We now find ourselves in a world where being able to sift through the avalanche of tools, frameworks, and techniques to pick out the ones that are useful (and might be around for longer than 6 months) is an incredibly valuable skill. But if you’re not careful, grabbing unproven new tools or frameworks can have a detrimental effect. They can lead to a ton of accidental complexity, or even worse, a dead end if that framework dies off before crossing the chasm.
Is there hope?
There are certainly more reasons we could discuss regarding why building software takes so long. Things such as business needs changing more rapidly, enterprise architecture standards, or an increased emphasis on security. But the point is that what we are building in 2020 barely resembles the software we were building back in 2010, much less in 2000, and that is for the most part a good thing.
However, there are some downsides. It feels like we have returned to a point we were at in the 2000 to 2007 timeframe where every application was being constructed using the same tools, and many of those tools are getting progressively more complicated. Many of the tools and frameworks that are now popular are coming out of large organizations that solve problems that many businesses don’t have.
Because of this many smaller and medium businesses, and even departments within large organizations, are finding that their ability to execute on software is diminishing rapidly and they can’t figure out how to turn it around. They have started to turn to low-code and no-code walled gardens in order to increase the pace of development, but in many cases they are crippling the functionality, lifespans, and ongoing maintenance costs of the systems they are building with these tools.
In a future post, I am going to discuss the impact of accidental complexity on software projects, and how we can more effectively avoid it while ensuring we are still meeting the needs of the business.
Loved the article? Hated it? Didn’t even read it?
We’d love to hear from you.




Thanks to Justin for a very interesting article.
I have been a one-person software developer and publisher for the last 20 years. This allows me to make a living and at the same time to travel the world and work wherever there is reliable wifi available. I began publishing Windows software in 2000 and I have continued doing this since I quit my last job as an academic research assistant in 2003.
This way of living means I cannot work as a member of a software development team. In order to publish a program I must do the program design, the user interface design and implementation, code all the calculation needed and produce the results that the user wants in an easily accessible form. I do my own source control and testing (with zero tolerance for bugs)
It also means that (a) I am unable to develop software to solve hugely complex problems and (b) I am unable to learn, master and use the tools of software development that have developed over the last decade or two. In fact I mostly use just four tools:
1. Visual Basic 6 to design and implement the user interface.
2. Inno Setup to compile the installation program.
3. Rapid PHP 2018 to write PHP code supporting program functionality and to write the documentation for the program.
4. Visual C++ Compiler for some DLLs writen in C (not C++).
Using this minimal skill set I have developed and currently published about 26 Windows programs (and more no longer published) in the following areas:
1. Text processing and analysis (including word and phrase counting)
2. Encryption and security
3. Calendar conversion software (including Chinese and Celtic)
4. Astronomical software for astrological and astro-trading uses.
For the calendrical and astronomical software I have relied on astronomical algorithms developed by academic astronomers.
The tools I use for these programs are not complex, but the programs I have written using them range from fairly simple (e.g., calculating dates of equinoxes and solstices) to very complex (e.g. phrase frequency analysis and Chinese calendar date conversion).
These programs may be seen at my two sites hermetic.ch and planetary-aspects.com
Of course, being a one-person software shop means that there are severe limitations on the complexity of applications and on the range of devices supported (in fact, only Windows desktops and laptops running Windows 7 or Windows 10).
I present this as evidence that it is still possible for one person to write good quality software without relying on complex open source frameworks and libraries or in fact on any tools developed after about the year 2000 (although I may be the last such person). OK, call me a dinosaur, but dinosaurs never really went extinct.
Hi Jason…
Another fellow dinosaur here…
Unlike you, I worked in corporate development and consulting for over 42 years when I retired in 2014.
Prior to my retirement I did produce one commercial product that worked quite well but never sold as the environment it was designed for went out of favor (Remoting). After I retired, I developed a SQL Server Source Control system for individual developers. It worked as well as the two major competitors it was designed NOT to compete with.
Now, I am on my third attempt at trying to develop a commercially viable piece of software; an individual document management system. It is nearly completed.
Like you, I have used a limited set of tools, most of which could be used in either the enterprise, small to medium businesses, or by individual developers.
These basic tools are really all one requires to develop high quality software. Like you, I test my software until I can find no further defects in the software. As a result, all of my products have perfoprmed in the same fashion as all my corporate development has done; with no defects and no worries on my supervisors’ parts or that of my clients’ that my software would cause any production issues.
This all being said, one of the major causes of complexity in software development, which has always been an impediment to quality productivity is the ridiculous demand for unsuited deadlines in development efforts. This is a result of weak and incompetent management that runs up and out of the technical departments right up to division heads and the like. Deadlines, cause their own deference to the development of complexities, which often include defects. Deadlines cause stress and other factors, which often disallow most developers from thinking out their designs and problems clearly with time to tinker with the best solutions.
And in recent years, we have had the constant trauma of changing tool-sets; all with the promotion that they will generate better software faster. They never do; they just add to the quagmire of existing complexity that most developers today must contend with.
There will never be a way to eliminate such inherent complexities within software development until the underlying stupidity is removed; from constant tool changes to incompetent management, it is not a battle with a lot of hope that it can be won. It is a Human condition that has been with us since computer technologies first became commercialized and moved beyond the qualified personnel that controlled a lot of the development and innovation.
There are of course, many remedies for such issues such as standardized software engineering practices but such implementations are most often thwarted by management who is more interested in getting a product out the door than its quality.
The other problem comes from many of our own colleagues who are all looking to develop the next great panacea for everyone’s development issues. This is where the world of Agile, DevOps, and the like have sprouted from all causing their own issues; many of which are a result of an elimination of common-sense.
In the current development environments in large business concerns (and even many medium sized business organizations) with both the internal and external market forces acting upon them, software development quality has become increasingly a thing of the past. In 1995 the Boeing Aircraft Corporation won the international award for both the software and hardware development of the 757/767 airliners. Now look at this once pinnacle of aviation quality with the 737-Max and the incredibly stupid decisions that led to the current situation. The 787 project exhibits similar but lessor known issues.
Small teams and individual developers such as us can and do in fact create a lot of quality software products. However, with the destruction of our software, cottage industry, which was quite solid in the 1990s and through the early 2000s we have been left with a limited number of avenues to promote our wares.
I am afraid that the “change” our field always touts has been more of a detriment than a plus for many of us, considering that so much is about the money…
Started being a one-developer shop in 2015 and it’s been surprising how easy software becomes when stakeholders don’t want to release things before they are ready.
In fact, being a micro-ISV is actually a lot easier than keeping up with the insane demands of the modern development team. A key reasons is that: you finally get access to customers, you get to do your own user research (features to do, or more importantly NOT DO), and development and business incentives are perfectly aligned.
I now release my own software when I feel like it’s ready, and customers consider the brand reliable. There was absolutely no software challenge at all. It’s a really simple trick that more development team could experiment!
Software is not actually that difficult, it has many decision that are debt and design decisions and should be taken seriously.
One other aspect is that of development by college educated folks with little field experience. They grasp many new technologies and immediately seek to apply them to the problem at hand, or develop new tools simply by not realizing that something already exists.
And then there is the aggrandizement of combining marvelous new tools ( they think they are new, anyway) For example, ROS, Just because this is what I am working with right now. There is a plethora of background code written in C and C++, Python, ADA, and probably mathematica and others. This product then binds them together with a messaging service which is ROScore. To manipulate and glue the bits together, you have XML, YAML, python and C bindings among others. Add a graphical IDE with full world simulation which then needs a script file to launch the works, packaging tools and a complex name space.
Now to be fair, this is to simulate and control a physical robot in real space time with real navigation and mapping capability including things like ultrasonic ranging, image processing, spatial resolution and on and on. Add in the ability to fully simulate mechanical characteristics such as mass and inertia, and to provide the simulation with PID capability, and it is a complex real world problem. And I don’t have any idea how to do it better, at least at this time.
In short, you don’t build a skyscraper without knowing that you cannot pull water more than 32 feet, you cannot avoid sway with out compensation, you cannot avoid wind disturbance without knowing a bit about aerodynamics, and you cannot allow harmonics to build in the structure. A complex structure requires complex knowledge, complex tools, and integration over time.
Even AI is not instantaneous!!
I’ve been a software developer as well as a UI artiste over 19 years. It’s been quite a trapeze act so far. I derive my means of living from the dreary hands of my commerce minded employers. And I feed my soul by moonlighting as a developer for the very small and the medium of enterprises. And I’ve learnt much from the disparate world views both of them bring to my perspectives.
I’ve seen fads come and go. I’ve seen dinosaurs like Microsoft and Oracle transform into the most forward looking of predators on the IT landscape. Supreme Predators. I’ve seen book sellers like Amazon become Cloud Giants and blaze a new path to glory.
I’ll also need to mention the numerous dead bodies of the once nimble and agile (maneuvrable) that have rotted away. Honourable mentions of companies like Sun, Xerox, Borland, Netscape.
The one law that binds them all is “survival of the fittest and the strongest”.
The churn in the software industry and the resulting complexities are but the fog of war for the dominance of this very important battleground in the mindspace and the culture space of the consumers of software.
Take for instance, the fads and the marketing slogans.
1. Year 2000 Bug. – Modernize now or the 2K Bogeyman will fire nuclear missiles into the heart of world.
2. 1990 – The future is the Web. And It was.
3. 2000, 2011 – The Cloud, SAAS, PAAS and it’s sister ideologies.
4. 2001 – Agile, Scrum, Kanban and it’s other variants.
And many more that I have skipped over.
The complexity of building software also arises from the need to evolve the marketing angle in the minds of the really big consumers of Big Software. The very real need of the Software Industry to capture a lion’s share of the next year’s IT budget spawns a host of “revolutionary” ways of developing, maintaining and consuming software licenses and the myriad of ways in which to keep the consumer hooked and pumped up with the latest spawn of the new fad. If the industry does not create the problems and the complexity themselves, how can they sell the latest and greatest of the new generation of problem solvers. Software tools, development, maintenance, protocols like Agile, consumption patterns like the Cloud are really just instruments in this war. It is a multifaceted one that requires us to look at the core of the situation.
The heart of the issue is Darwinian Evolution and the winnowing out of the herd of wonderful development tools and practices that are simple, clean, beautiful and numerous. It’s replacement with a few standardized major paths and protocols that are monstrous, aggressively competitive, hugely complex beasts that voraciously consume the allocated resources for the year ahead.
Of course! How did I not think of it! That which consumes no resources has none to spend. And a perfect solution leaves nothing more to be said. Occasionally, inherent attractiveness will beat marketing etc.
My thoughts are that for complex systems outside the domains of computing, the data sciences and computer infrastructure, we have made little progress in effectively modeling essential complexity into code. That I contend is why software continues to take so long.
We are no better today at modeling a complex payroll system or airline reservation system into code than we were 40 years ago. One might argue that accidental complexity has generally increased. Can one assume therefore, that the ratio of essential to accidental complexity has widened?
Good post. You hit a lot of the changes I’ve seen since coming to the field in 1992.
One important point, particularly for developers who do internal development, is user areas being a rate-limiting factor. They want software customized for their processes but they don’t have documented processes. What they have is more like folklore. They also have no idea what to test in the user-acceptance testing phase. Factor in employee turnover, which seems all too frequent nowadays, and you develop a lot of friction working against a software project with well-defined goals.
As my team works with different departments, we encourage them to think about their processes and exceptions and document them. We also explain the different types of testing and show examples of user-acceptance tests we do with other departments. It’s a slow learning process that they don’t internalize until a project goes sideways.
You mentioned distributed applications bringing complexity. I can’t agree enough. Most software I wrote until 3 years ago was < 5 tier. Now I'm writing applications interacting with several endpoints but also many points between. Areas like error handling are much more complex and, I'm coming to believe, require a different approach.
I could write a book about this subject, so instead I will leave a couple of comments:
1) New generation programmers are for the most (not all) terrible programmers, interested in the next cool new thing that requires less effort on their part. But is instead way more complex than their previous tool, so the code coming out is inefficient and often unreliable crap. To use any tool well you MUST have a DEEP DEEP DEEP understanding about what the tool does under the hood!!!!!!!
2) By sticking to well tried and used tools you avoid much of the accidental complexity. Sadly market leaders like M$ are the most to blame for this not being taken to heart by their ever changing tools. Tools which are NOT designed to make programming easier, but to make it harder for the same programmer to switch to one of the many MUCH BETTER tools out there. In concert with ignorant managers, this tool churn causes much of the inefficiencies in our industry.
I believe the key to reduce this accidental complexity is building modular systems. Sadly though, while we employ a plethora of modern technologies to build products these days, integration and interoperability between multiple products continues to remain an issue. To give an analogy, I do not need to worry when I have to change the tyre of my Honda. I can buy a bridgestone, but I might as well buy a MRF and both will fit and the tyre can be replaced by me/another less skilled person. Come to software, even for the most standard of integrations, teams continue to go through the entire cycle discussion, design, build, test and deploy. There is no plug and play. The way to reduce the accidental complexity IMHO is by having more and more of the products operate with a plug and play.
Thanks it helped me a lot
Thanks for such insightful article. Building software is a complex and multi-layered process demanding advanced skills of developers and enthusiasm combined with hard work. Full dedication to the project as well as implementation of complex tools, testing stage and bug elimination may take time as well as resources, however the successful end product is worth it!