

(I put a little call stack tutorial at the end, so if you are confused, skip to the end. Then restart. Rinse and repeat.)
A while back I made a post entitled don’t be clever. In this post I postulated that in the modern world of programming we need to be more cognizant of making our code readable and grokkable than to make it clever or sneaky. In this post I also used one of my favorite programming quotes of all time (which I will put here again because it is awesome):
Programming is not like being in the CIA, you don’t get credit for being sneaky.
Steve McConnell
And that is so true. For 99% of the developers out there, no one is ever going to pat you on the back for being sneaky. You’re probably more likely to get punched in the face for it when the team has to spend the weekend debugging a piece of your clever code.
I decided to write this post today because I came across this little gem (which I did not write!!!) that epitomizes exactly why you should not do this. Keep in mind that this is not the exact block of code, but it does mimic part of its functionality. Lets look at the code first:
private static void DoSomething()
{
StackFrame frame = new StackFrame(1);
string methodName = frame.GetMethod().Name;
if (methodName == "Main")
{
//do something
}
else
{
//do something else
}
}
Okay, so what does that do? Well, it looks at the previous stack frame by instantiating a StackFrame object with “1” as a constructor parameter. Then it gets the method of that stackframe and uses it to determine what to do. Pretty clever, huh? A little too clever if you ask me.
So, I have thrown together a little example of why you don’t do this. Never ever do this. Only in controlled laboratory environments should this type of code be written, and even then you should be careful that it doesn’t escape. So here is my sample app:
static void Main(string[] args)
{
string methodName = ShowMyMethodName();
string message = "Look where I am coming from: {0}";
Console.WriteLine(String.Format(message, methodName));
}
private static string ShowMyMethodName()
{
StackFrame frame = new StackFrame();
return frame.GetMethod().Name;
}
What this does now is it just pulls the current stack frame and displays the name. The reason I changed it to do this will be clear in a moment. So, what happens when we run it?
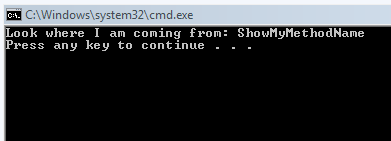
Huh, wait… it worked. You are probably laughing with satisfaction (if you are slow) or waiting patiently (if you are smart) because you know that I would not have written such an idiotic blog post.
It appears to have worked fine, but now let us compile it in release mode and see how far we get. You do run your production apps in release mode, right?
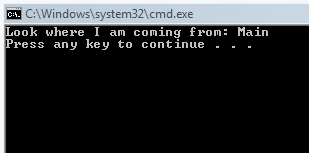
Now what happened? We are pulling the current stack from, but it is showing that we are calling from Main. But that code isn’t in Main, it is in “ShowMyMethodName”! To give you an idea of what just happened, look at this:
static void Main(string[] args)
{
string methodName = ShowMyMethodName();
string message = "Look where I am coming from: {0}";
Console.WriteLine(String.Format(message, methodName));
}
[MethodImpl(MethodImplOptions.NoInlining)]
private static string ShowMyMethodName()
{
StackFrame frame = new StackFrame();
return frame.GetMethod().Name;
}
That worked, and it was all due to that little Attribute we put on our method. In case you are wondering (it is pretty self explanatory), that keeps the method from being inlined (again, tutorial at bottom of post).
Oooooooooooooooh. Now it becomes all too clear. Those darn little compiler tricks. Well, actually not a compiler trick, a JITer trick. The reason we know it is a JIT optimization and not a compiler optimization is because if we use reflector on it (man I love reflector), we still see our happy little methods:
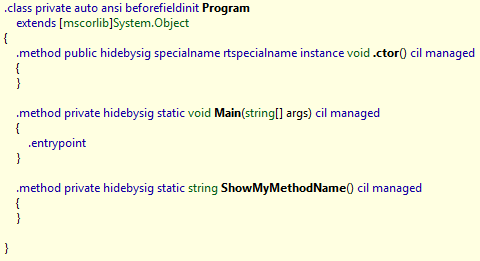
So, even though it compiled as though it would work, it still doesn’t work. At runtime the “ShowMyMethodName” method isn’t there, it was optimized out! The developer that wrote that code above was lucky that the method that they were coming from wasn’t being inlined, but they got lucky!
An even worse situation would have been if I was working on an x86 computer and it worked in debug and release mode. Well the 64-bit JITer might have different heuristics for determining which methods should be inlined. So, it might work on your box in all modes and then not work in production! Lets just say that being clever is bad! Production only bugs are the worst kind of bugs, because far too often our output from the running program is inadequate.
So there you have it. Being tricky will get you in trouble. Potentially big trouble. If you are ever writing a line of code and there is something in the back of your mind that is just nagging at you, saying “you probably shouldn’t do that.” Listen to it. Please, listen to it. If you ever see this:
long value = GetSomeLongValue();
UseSomeIntegerValue((int)value);
Think if you were a doctor: “Well, this isn’t big enough, but if I just squeeze this then I think it will fit in there.” Yeah, that would be a career ending choice. We programmers have it so good.
Stack Tutorial
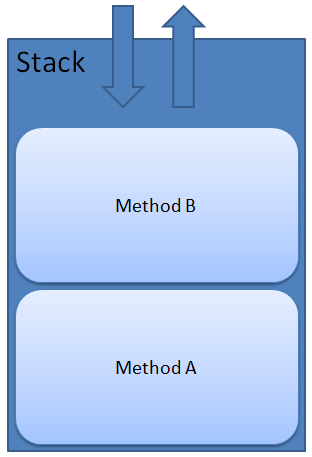
Okay, so for those who aren’t in the know, I’m going to give a quick and dirty explanation of how a call stack works. Each time a method is called a new stack frame is pushed onto the stack. It is called the stack because it is a stack data structure, and by that I mean it is LIFO (Last In First Out). You push something onto the top, and then you pop that last item off. The stack is where all of a methods local variables are kept (or pointers to the heap, but that is for another time). So, lets say we call MethodA and then MethodA calls MethodB. Well first MethodA’s stack frame is pushed on the stack and then MethodB’s is. So, the stack would look something like this:
Okay, so, when I was talking above about methods being inlined, what that means is that the compiler (or in our case the Just In Time compiler, also know as the JITer or JIT compiler) can look at a method and say: “Hmm, that method looks short or rarely used or whatever…I think it would be more efficient to move the operations in that function and just stick them in wherever that method is called. Like this:

So, what happens is that MethodB essentially disappears. This allows the application to avoid the overhead of calling another method and pushing another frame onto the stack. While this overhead is negligible in most cases, it is generally assumed to be a safe optimization and therefore the compiler does it.
Loved the article? Hated it? Didn’t even read it?
We’d love to hear from you.




See http://weblog.ikvm.net/CommentView.aspx?guid=245f4ca5-0512-4e66-a6c6-fa4d4af697ef for how Eclipse does (or did at the time it was written) this when run on IKVM. The comments are also interesting in that they appear to defend this practice. Which, BTW, I agree should NOT be done.
Now you’ve done it. Everybody’s going to be NoInlining everywhere so they can get away with stuff like this.
@Mark That is interesting, they are operating under the assumption that the runtime call stack should still show methods that have been inlined. I fail to understand how that would work, but okay. If the method was inlined then it isn’t in the callstack, so are they just supposed to write code to insert fake stackframes? Like you, I’m not convinced.
@Will Ha, lets hope not!
Thanks man, I had no idea compilers can do that..
@Benny Compilers have all kinds of neat tricks. If you’d like to see another one, check out this post about tail recursion:
http://www.codethinked.com/post/2008/04/Immutability-and-tail-recursion.aspx
Sounds like a crappy implementation of stacktraces to me. You shouldn’t have to know if a method is inlined or not. The stack trace is a tool for debugging and how are you supposed to debug if you can’t get back to the original line of code?
@kdavies It is a debugging tool, and it is great for getting info while in debug mode, and it even provides pretty good info while in a release build. The problem is that StackFrame pulls the method calls off the stack, and inlining is a JIT optimization. So I don’t really know how you could change it other than to have the compiler write some kind of metadata for [b]every[/b] method that the JITer would have to respect and keep in place, since the compiler does not know ahead of time what methods might be inlined.
[quote]@kdavies It is a debugging tool, and it is great for getting info while in debug mode, and it even provides pretty good info while in a release build.[/quote]
@justin I’ve had to use this before in a .net 1.1 app to determine something about my caller (not sure what, it was a while back!). Sometimes I wish you could call this.CurrentMethod.Caller to get type information about your caller. Javascript has this I think.
Cheers,
Luke
That is what StackFrame(1).GetMethod().Name allows you to do, but you have to be sure that you check the result of StackFrame(1) to make sure that there is a method. The .net runtime only inlines very small methods, most of the time the above code works fine.
I would recommend just wrapping it in your own class to handle all the heavy lifting, so you could just call "CallStack.GetLastMethodName()". Hmm, maybe that is something for a future project.
Not sure. I’ve always liked clever code. Shouldn’t the maintainer be able to read it? As long as a unit test is provided reducing the boilerplate seems like the right way. Last week we have an interesting discussion on the groovy mailing list which incolved the following snippet:
def m = ({LazyMap.decorate([:], curry() as Factory)}).call()
Crazy code, isn’t it? But it does what it needs in the most compact way.
For the record, the code examples in both of your posts were not what I would call clever. The first (the multiply by four) was convoluted without any need. That’s pretty dumb IMO. The second was just some random code with a nasty bug.
Regards
@Jose There are a time and place for everything. Everything is a sacrifice in other areas. If you sacrifice simplicity and readability for cleverness then you had better have a very good reason for doing it.
The whole point of my posts is to strive for simplicity and not cleverness. You show me someone who strives for cleverness, and I will show you someone that causes problems.
The piece of code you have in your post, if it does the job and gets the work done in a way that would have been overly complex otherwise, then you have succeeded. But, like in this post, there is a piece of overly clever code that is written to do something that otherwise would have been very simple, then you have failed.
And yes, the code in the previous post was contrived, and I realized that. In this post though, I would call pulling the stack and looking at the previous method to figure out what to do "clever". Maybe we have a different idea of what clever code is, all I know is that the code is needlessly complex.
Thanks for the feedback!
Clever is the new stupid.
Nice article, Justin.
Kevin
@Kevin "Clever is the new stupid" Ha ha ha, love it.
http://mazykazerooni.com/post/33058007/go-to-work-send-your-kids-to-school-follow
Yes, you can write your code for dummies..
@Jose Somehow I doubt that we are on different sides of the fence on this issue. I just think that we are expressing it differently. When I look at software I see one of the most blatant examples of the laws of entropy at work, and therefore I strive for simplicity. A programmer who enters into his work striving for the most simple solution available, will end up staving off entropy as much as possible. And your system, your schedule, and your co-workers will thank you for it.
Sometimes clever code *is* the most simple solution, and in that case, I’m all for it. If a clever solution (that is well documented) greatly simplifies the codebase, then I would say that you have tipped the scales with the clever code.
If on the other hand, you approach your work, constantly looking for clever solutions for no other reason than to be clever, you are introducing more entropy into the environment. In my mind, a programmer who strives for clever will find clever ways to get around a problem, rather than trying simplify the action in order to get a resolution. Like I’ve heard many times before "The best code is the code that you didn’t write".
Now, when I am working in my free time, I tend not to follow these rules myself. I am a programmer, I like clever and tricky things. But the behaviors that will help you out in a 3k line projects will fall apart in a 300k line project.
That’s probably true. Many times I like to play as devil’s advocate. In fact, I’m a strong supporter of things like static typing even though it adds boilerplate. But the title of the post was misleading (I firmly think everybody should strive to implement the best solution for a problem which involves clever code by definition) 🙂
I have recently fought this very problem in some logging routines. I wasn’t aware of the attribute so I got cleaver and added a try/finally block… I’ll go fix it now, thanks for the info!
I love a good rant that puts a clever kludge in it’s place!